News (2019)
Happy St David’s Day everyone! The CorCenCC team has been busy promoting the project and encouraging participation on the day of our Patron Saint! Here are some photos of the day’s activities.



The Team would like to extend sincere thanks to everyone who has ‘done the little things’ (and big things!) by contributing to the corpus. Thanks also to our project champions and to all those who support us.
If you would like to contribute Welsh language data to the project, but are unsure of how to do so, follow our social media accounts https://twitter.com/CorCenCC and https://www.facebook.com/CorCenCC/, download the app or drop us a line at corcencc@cardiff.ac.uk!
WP1 – Your help needed
The Corpws Cenedlaethol Cymraeg Cyfoes is looking for contributors! Before Christmas, we published our map showing that our spoken Welsh totals were close to 100% for most of Wales, with just a few areas and dialects lagging behind. If you know Welsh speakers from Merthyr Tydfil, Conwy, Flintshire or Anglesey, we need their contributions! They can do this easily and from the comfort of their own homes via our crowdsourcing app (on Android and iOS).
Have a go on the app
Our app allows you to record and send your Welsh in a natural and simple way. We first ask for your permission and your personal details (so that you can tell us to remove your data if you ever change your mind) in the app itself. Then you will be asked to make two recordings. The first is for everyone present to give their consent. The second is the fun part! Maybe you have always liked the way a particular family member speaks and you would like to share their uniqueness with the corpus. Or perhaps you have entertaining conversations with your friends at lunch and you are happy to share a little with us! Whatever the circumstances, we are looking for Welsh language as it is used in everyday, natural settings. Our app is a great way to help us out and to prompt an interesting conversation at the same time!
If you are not too confident with using new apps on your phone, you can follow our detailed instructions here: https://www.corcencc.org/app/
Send us your texts and e-mails
In our corpus of 10,000,000 words, we are looking for a balance of different kinds of language. So far, we have exceeded our targets for language from blogs and websites – happy days!
We are looking for more people to send us their Welsh text messages and e-mails (no matter how many English words they include)! They can be professional or personal and we will anonymize everything before use. If you are keen to contribute to building the Corpus, please forward your e-mails to us at CorCenCC@cardiff.ac.uk (and we will need you to sign a consent form for us before we can use anything you contribute). Tell your friends too! We are collecting messages via our WhatsApp. Simply add +44 7542 348512 to your WhatsApp and send us a quick hello! One of the team will then contact you as soon as possible with instructions on how to forward all text messages you are happy for us to include in one quick batch.
Keep talking
If you would like more information before you share your language data with us, you can talk to us using the same e-mail address or even via Twitter @CorCenCC or our Facebook page CorCenCC. We will be very happy to hear from you!
If you would like to contribute more examples of your speech and text to the corpus, but you do not have time just now, you can follow us on our social media accounts for reminders and updates about the project.
CorCenCC query tool demo
The new year has seen some major progress on CorCenCC’s front-end corpus query tools, which we are extremely happy to release this month as a beta version. The tools are the major development of WP5, which focuses on the infrastructure required to build and maintain the data and ensure that people can dive into the data when it’s ready. Now that we have what we identified as the major functionality up and running, we’re hoping that releasing this beta version of the query tools will bring us some vital feedback that we can use to refine and expand the tools’ features between now and the end of the project.
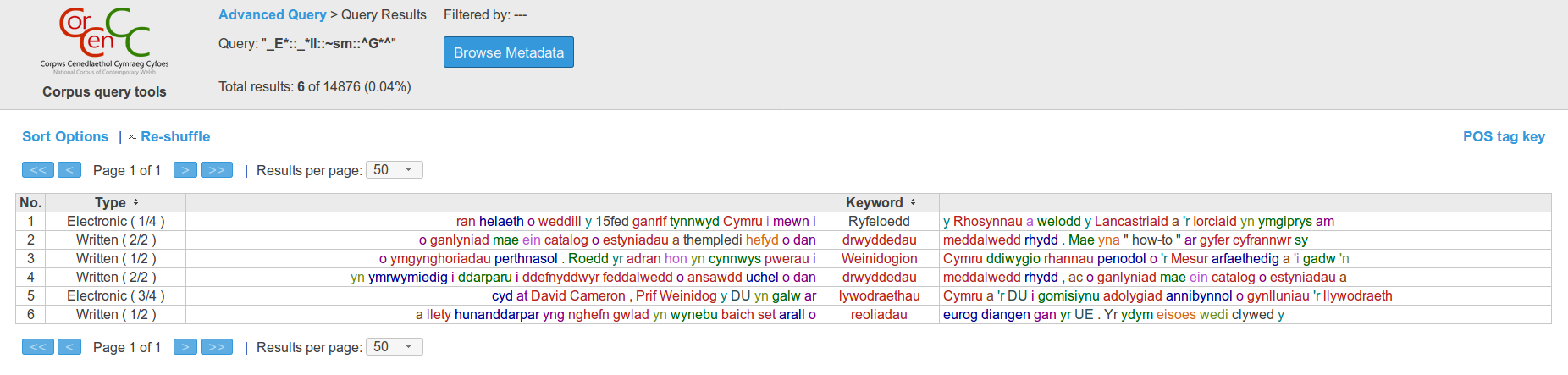
The tools currently operate using a very small corpus of around 15,000 words, which we’ve used throughout CorCenCC to evaluate our various software tools, but of course we’ll be replacing this with the data collected by the WP1 team over the next few months. Using the beta version, though, the full range of current functionality can still be accessed and experimented with. This includes:
- Keyword-in-context (KWIC) concordance lines:
- Search for words (or a sequence of words) in CorCenCC, and see the results in context, with the surrounding text to the left and right displayed. Our query tools offer two ways to produce concordance lines.
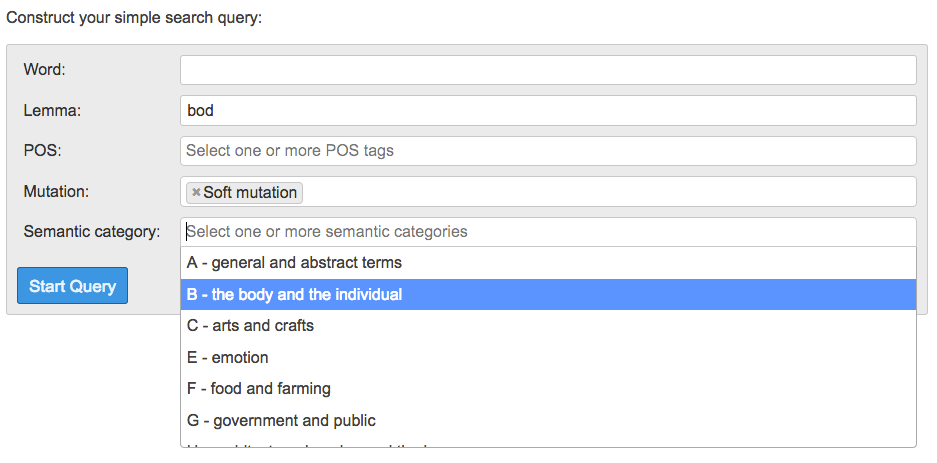
- Select ‘Simple Query’ > use our handy form to search for individual words, restricted to specific mutation types, parts-of-speech (POS; syntactic categories), and/or semantic categories as appropriate.
- Select ‘Full Query’ > use our bespoke query language to chain together more complicated queries and search for sequences of words (full instructions are available on the tools themselves).
- Search for words (or a sequence of words) in CorCenCC, and see the results in context, with the surrounding text to the left and right displayed. Our query tools offer two ways to produce concordance lines.
- Frequency lists:
- Produce lists of the most frequent lexical items in the corpus – whether that be the most common words or the most common lemma forms.
- Select ‘Frequency List’ > choose whether to create a list of ‘words’ or ‘lemmas’ > choose whether to constrain the list to specific POS tags, mutation types and or semantic tags.
- N-Gram analysis:
- Produce lists of the most frequent n-grams (also known as ‘clusters’ of words) – for example, the most commonly occurring sequences of three words used together in the corpus.
- Select ‘N-Gram Analysis’ > choose whether to create clusters of ‘words’, ‘lemmas’, or ‘POS’ tags > choose a gram size to produce a list.
- Collocation analysis
- Produce lists of collocates – words most commonly found occurring alongside a given search term within a given contextual window (n-words either side of the search term) – ranked according to the strength with which they co-locate.
- Select ‘Collocation analysis’ > enter a search term (word) for which you want to find collocates > choose a window size within which to consider collocates (plus or minus 7 either side) > choose a ‘strength’ metric by which to rank collocates (available metrics described on the tools).
- Keyword analysis
- Produce a list of keywords – those whose occurrence is statistically significant compared to their rate of occurrence in a comparable sub-corpora. For example, find out which words are statistically common in a sub-corpus consisting only of spoken corpus data, compared with a sub-corpus consisting of written and electronic data.
- Select ‘Keyword Analysis’ > click ‘Sub-corpus A’ and select options to include (or not) data for your main corpus (subset of CorCenCC) > click ‘Sub-corpus B’ and select options to include (or not) data for your reference corpus (subset of CorCenCC) > choose a method by which to rank the ‘keyness’ of the words (described in more detail on the tools) > select the significance level at which a word is considered ‘key’
- Produce a list of keywords – those whose occurrence is statistically significant compared to their rate of occurrence in a comparable sub-corpora. For example, find out which words are statistically common in a sub-corpus consisting only of spoken corpus data, compared with a sub-corpus consisting of written and electronic data.
- Produce lists of collocates – words most commonly found occurring alongside a given search term within a given contextual window (n-words either side of the search term) – ranked according to the strength with which they co-locate.
- Produce lists of the most frequent n-grams (also known as ‘clusters’ of words) – for example, the most commonly occurring sequences of three words used together in the corpus.
These major functionalities are supported by additional features, including being able to:
- Sort results to the left and right of the search word(s), in order to visualise different patterns of Welsh language use;
- Filter results according to the various metadata we’ve been gathering, about contributions to the corpus and the contributors and speakers involved in them.
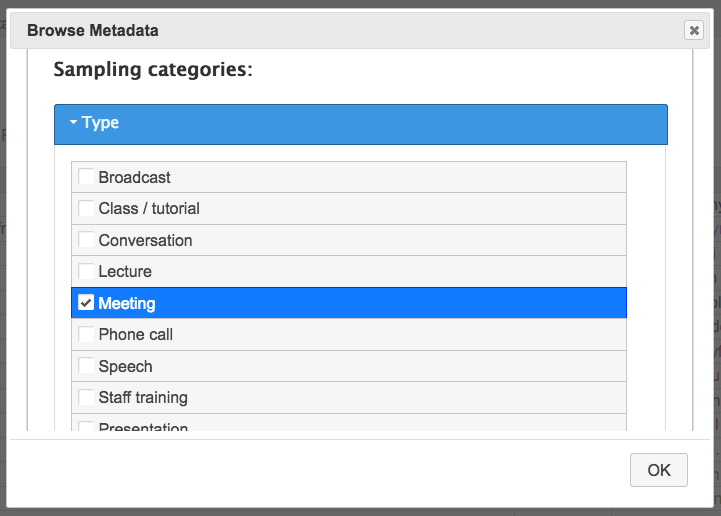
In November’s newsletter, we described how the development of the query tools has been informed by a survey we conducted on users’ preferences in existing corpus analysis and query tools, which has been interesting in helping us decide what functionalities to prioritise at this stage. In the same spirit, we’re also including an option to leave feedback in our beta version of the query tools – so please feel free to tell us what you think of them! We’re looking forward to seeing how people make use of the different features we’ve included, and your input is valuable in helping us decide what features we should include next.
Over the next couple of months, we’ll be reviewing all of the feedback we receive on our beta version of the query tools in order to include as much useful functionality as possible, to make the tools as effective as possible for highlighting how Welsh is being used in different contexts across the corpus data we’re collecting. Development of our pedagogical toolkit – by members of WP4 – is also well underway, so we’ll be working to link that to the query tools so that teachers and learners can utilise the data for their own lesson plans and study sessions.
So, please feel free to explore our beta version of the CorCenCC corpus query tools, currently located here – we look forward to seeing what you all think of it!
News (2018)
WordNet Cymraeg
Last month, three of the CorCenCC team members – Irena Spasic, Steven Neale and Dawn Knight – completed work on the WordNet Cymraeg project, which has been underway over a 3-month period in parallel with CorCenCC. WordNet Cymraeg is a lexical database of Welsh content words (nouns, verbs, adjectives and adverbs) grouped together as sets of synonyms, which are then linked to each other according to various lexical and semantic relationships. It follows the same methodology as WordNets in other languages, which have been crucial resources for determining the meaning of words in natural language processing tasks such as word sense disambiguation and text summarisation.
WordNet Cymraeg has been developed over a 3-month period, for which we were very pleased to be funded by the Welsh Government as part of their Grant Cymraeg 2050 scheme. In line with emerging trends in constructing WordNets automatically, we’ve leveraged bilingual dictionary information provided by our friends at the GPC (Geiriadur Prifysgol Cymru) to translate words from the English WordNet to Welsh, and then organised those words into Welsh synonym sets based on the original WordNet structure in English. We’re really happy with our resulting Welsh WordNet, which covers about 67% of what are considered to be the ‘core’ synonym sets for a new language – those 5,000 or so concepts that are the most common, and have the most relationships to other synonym sets.
We also had the opportunity to show our work to the funders and to the community as part of the recent Cymru Arloesol event at Tramshed Tech in Cardiff, at which a number of the projects funded by Grant Cymraeg 2050 demonstrated their progress. It was fantastic to be there to see the exciting ways that people are driving the development of Welsh language technology, and for our own Steven Neale to be able to give a presentation on the development of WordNet Cymraeg and the value it offers in that landscape. These are certainly exciting times for the development of technology delivered and available in Welsh, and Welsh natural language processing tools are going to have an important role to play in that.
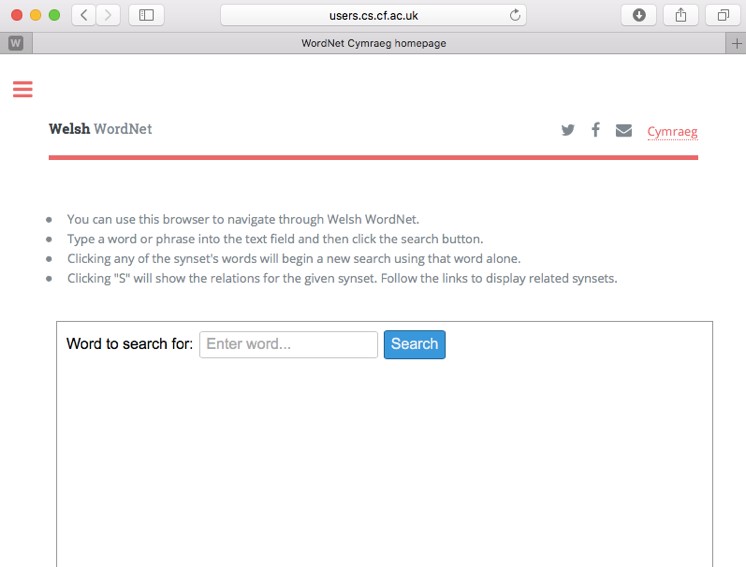
To find out more about WordNet Cymraeg, visit https://users.cs.cf.ac.uk/I.Spasic/wncy/index.html, or to start using WordNet Cymraeg, files can be found at https://github.com/CorCenCC/wncy.
CorCenCC newsletter – previous editions
- Issue 1: April 2016
- Issue 2: May 2016
- Issue 3: June 2016
- Issue 4: July 2016
- Issue 5: August 2016
- Issue 6: September 2016
- Issue 7: October 2016
- Issue 8: November 2016
- Issue 9: January 2017
- Issue 10: March 2017
- Issue 11: May 2017
- Issue 12: July 2017
- Issue 13: September 2017
- Issue 14: November 2017
- Issue 15: January 2018
- Issue 16: March 2018
- Issue 17: May 2018
- Issue 18: July 2018
- Issue 19: September 2018
- Issue 20: November 2018
- Issue 21: January 2019
- Issue 22: March 2019
- Issue 23: May 2019
- Issue 24: August 2019
Subscribe to our project newsletter